#White Papers
Edge Computing, Fog Computing o entrambi?
Informatica in-the-cloud
Che cos'è il cloud computing?
Una definizione semplificata di cloud computing è la potenza di calcolo fornita come servizio online. A seconda dei requisiti, è possibile noleggiare da un fornitore di servizi cloud l'hardware (Infrastructure as a Service, IaaS), una piattaforma (Platform as a Service, PaaS) o un software direttamente preconfigurato (Software as a Service, SaaS). Queste soluzioni sono particolarmente vantaggiose in caso di esigenze di archiviazione fluttuanti o se si vuole evitare l'acquisto di hardware/software propri. Un buon esempio sono i fornitori di servizi di archiviazione e gestione dei file online. Ad esempio, Google Drive è un servizio di questo tipo. In questo caso, i file non vengono archiviati su dispositivi fisici, ma piuttosto "nel cloud". Nelle applicazioni industriali, questi dati, che si presentano in varie forme, possono provenire da sensori IoT. Possono essere inviati a un servizio cloud come Microsoft Azure. A tal fine, i dati devono essere trasferiti dai dispositivi fisici sul campo al cloud. È qui che entrano in gioco l'edge computing e il Fog computing.
Approfondimenti ed esempi di edge computing
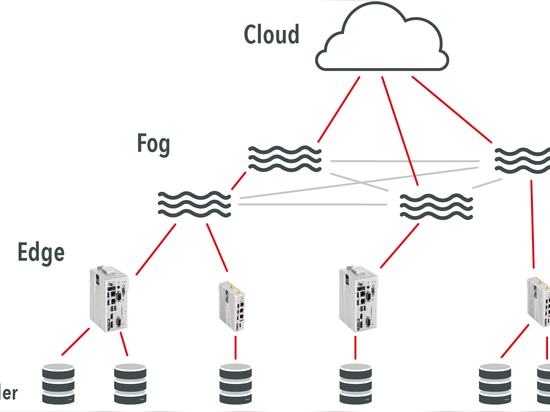
L'edge computing, a differenza del fog computing, si svolge direttamente sul dispositivo finale, cioè ai margini della rete. Con l'Edge Computing, i dati provenienti dai sensori collegati vengono raccolti, filtrati, compressi, se necessario crittografati e inviati. I cosiddetti gateway edge IoT possono essere utilizzati per la pre-elaborazione sul dispositivo finale. Utilizzando gli edge gateway, a differenza delle soluzioni integrate, è possibile prolungare la durata dei sensori collegati o la durata della batteria, poiché le analisi complesse vengono esternalizzate. Un esempio di utilizzo sensato dell'edge computing è rappresentato dai contatori intelligenti. I contatori intelligenti sono contatori elettrici intelligenti che producono una grande quantità di dati effettuando misurazioni a brevi intervalli. Con l'aiuto dell'Edge Computing, in questo caso attraverso la soluzione embedded, i dati possono essere ridotti prima di essere trasportati ulteriormente sulla rete. Maggiori informazioni sull'Edge Computing sono disponibili nel nostro breve filmato esplicativo.
Approfondimenti ed esempi di Fog Computing
Il fog computing è un livello di elaborazione tra il cloud e l'edge. Con l'edge computing, i flussi di dati di grandi dimensioni possono essere inviati direttamente al cloud. Il fog computing, invece, può ricevere i dati dal livello edge prima che raggiungano il cloud. Quindi, solo i dati rilevanti vengono archiviati nel cloud. Allo stesso tempo, i dati irrilevanti possono essere cancellati o analizzati nel livello Fog per l'accesso remoto o per informare i modelli di apprendimento localizzati. Un buon esempio di Fog computing potrebbe essere un'applicazione integrata in una linea di produzione in cui un sensore di temperatura collegato a un gateway edge misura la temperatura ogni singolo secondo. Questi dati verrebbero poi inviati al cloud per monitorare i picchi di temperatura. Immaginate che tutte le misure di temperatura, ogni singolo secondo di un ciclo di misurazione 24/7, vengano inviate al cloud. Con un livello Fog, l'edge gateway invierebbe prima i dati al livello Fog attraverso una rete localizzata. In base a determinati parametri, si decide se e quali dati inviare al cloud. In questo modo si riduce il traffico di dati. Per le semplici letture della temperatura, questo risparmio di dati può sembrare trascurabile. Ma immaginate l'impatto se questi flussi di dati costanti fossero pieni di informazioni molto più complesse o di file di grandi dimensioni, come immagini o video.
Vantaggi del Fog Computing
Un vantaggio è l'efficienza del traffico dati e la riduzione della latenza. L'implementazione di un livello Fog riduce i dati che il cloud riceve per la sua specifica applicazione incorporata. Ciò consente di rispondere direttamente ai dati del livello Fog. Altri vantaggi sono la riduzione dello spazio di archiviazione necessario per l'applicazione cloud e il trasferimento più rapido dei dati grazie al volume ridotto.
Svantaggi del Fog Computing
È chiaro che il Fog computing non può sostituire l'edge computing. Tuttavia, l'edge computing può funzionare anche senza il fog computing. Il Fog Computing è un sistema complesso che deve essere integrato in un'infrastruttura esistente. Questo comporta uno sforzo notevole. Pertanto, il Fog Computing non è adatto a tutti gli scenari. Tuttavia, per alcune applicazioni, i vantaggi di cui sopra possono essere interessanti se si utilizza un'architettura di dati edge-to-cloud diretta.
Differenze tra Edge Computing e Fog Computing - Funzionalità
I termini Fog ed Edge Computing sono spesso usati in modo ridondante. Tuttavia, oggi esiste una demarcazione ben definita tra le due soluzioni. Di conseguenza, Fog Computing è un termine generico per la pre-elaborazione dei dati nella rete locale, mentre Edge Computing è una forma speciale di pre-elaborazione dei dati. Un dispositivo Fog conosce tutti i dispositivi presenti nel dominio. Durante le analisi, è possibile accedere agli altri dispositivi e comunicare con essi. I dispositivi Fog possono prendere decisioni in base ai dati ricevuti e memorizzare piccole quantità di dati. L'Edge, invece, esegue compiti come il filtraggio e la sintesi dei dati. I dispositivi edge non si conoscono tra loro e quindi non interagiscono.
I nodi fog sono di solito dispositivi già esistenti nella rete. Si trovano in un ulteriore livello gerarchico tra i dispositivi finali e il cloud. L'edge computing, invece, si svolge direttamente sul dispositivo finale o addirittura al suo interno.
Scegliere l'hardware e il software giusti
L'idea del Fog Computing si basa sull'utilizzo di dispositivi già presenti nella rete (ad esempio, router industriali, gateway, server). Ciò significa che non è necessario un hardware speciale. Tuttavia, i dispositivi già esistenti devono essere integrati in una rete Fog con un software appropriato. Questo software è oggi disponibile presso molti fornitori. Per lo più sono gli stessi fornitori di cloud a fornire soluzioni software per il collegamento in rete dal livello Fog al rispettivo cloud.
L'edge computing, invece, si basa principalmente sull'hardware. Le suddette funzioni di edge computing vengono eseguite su molti dispositivi finali. Questi sono integrati nei sistemi esistenti e sono forniti dal produttore. Se i dati di un dispositivo finale privo di tale funzionalità devono essere elaborati nell'edge, è necessario un hardware aggiuntivo come un gateway edge. I dispositivi dispongono di un'ampia varietà di interfacce per collegare diversi dispositivi finali.
Per quanto riguarda l'hardware necessario o il tipo di computer industriale, un edge gateway può essere facilmente utilizzato per lo stesso scopo di un server Fog. Il motivo è che esistono differenze nella raccolta e nell'elaborazione dei dati, ma non nelle funzioni e nelle capacità dell'hardware.